")
TLDR; Agent Integrity is the assurance that an AI agent behaves as intended, maintains alignment with authorized purposes, and operates within sanctioned boundaries across every interaction, tool call, and data access. It encompasses not just what an agent can do (the domain of permissions), but also what an agent should do (based on intent), what an agent actually does (behavior), and whether those three dimensions align throughout the entire workflow.
For most of the past two years, the conversation about AI in the enterprise centered on chatbots and copilots: systems that answered questions, drafted emails, summarized documents, and occasionally hallucinated. Security teams worried about employees pasting confidential data into ChatGPT. The threat model was familiar, essentially a new flavor of data loss prevention.
That era is ending. As 2026 begins, organizations are deploying AI agents that don’t just respond to prompts but take action autonomously. These systems manage calendars, send emails, query databases, execute code, browse the web, and coordinate multi-step workflows across enterprise infrastructure. They decide what steps to take based on their interpretation of what you asked for, and they do all of this using your credentials and permissions, often without asking for approval at each step.
This shift from AI that talks to AI that acts creates a security problem that traditional tools were never designed to solve. An agent with authorized access to your email and cloud storage can use those permissions to exfiltrate data, and every action it takes will pass the permissions check because the credentials are valid, the API calls are authorized, and the security logs show normal activity. The behavior, however, may have nothing to do with what you actually asked the agent to do.
Agent Integrity is a framework for addressing this problem. It shifts the security question from “can this agent access this resource?” to “should this agent be accessing this resource right now, for this task?” That shift from permission to intent is what distinguishes agent security from traditional access control, and it represents a fundamental change in how organizations need to think about securing autonomous AI.
The Current Landscape: Agents Are Already Everywhere
Citigroup launched a pilot of agentic AI in September 2025 involving 5,000 employees, with 175,000 workers now having access to some form of AI tool across its operations.[1][2] The platform, called Citi Stylus Workspaces, allows a banker to issue a single prompt that researches a client, pulls data from internal and external sources, compiles a profile, and translates the findings into another language. “A couple of years ago, you could do agentic things with the early versions of the models that were available then,” Citi CTO David Griffiths told the Wall Street Journal. “But they weren’t always very reliable. They weren’t always very good at invoking tools. But they are now.”[1]
Walmart consolidated dozens of internal AI agents into four “super agents” in July 2025, each serving a different constituency: customers, employees, suppliers, and developers.[3] The company’s AI tools saved 4 million developer hours last year.[4] Salesforce reported that more than 18,500 organizations are deploying agents through its Agentforce platform, which processed over 3.2 trillion tokens in 2025.[5] ServiceNow announced a three-year partnership with OpenAI in January 2026 to embed frontier AI agents into its platform, enabling speech-to-speech automation and no-code workflows for enterprise IT.[6]
Gartner predicts that 40% of enterprise applications will include task-specific AI agents by the end of 2026, up from less than 5% in 2025.[7] A KPMG survey found that 75% of enterprise leaders now cite security, compliance, and auditability as the most critical requirements for agent deployment, which suggests that executives recognize the risks even as they push forward with adoption.[8]
The security concerns are grounded in documented threats. OWASP released its Top 10 Risks for Agentic Applications in December 2025, identifying tool misuse, prompt injection, and data leakage as primary threats.[9] Palo Alto Networks warned that AI agents represent a new class of insider threat, describing them as “always on, never sleeping” systems that, if improperly configured, can access privileged APIs, data, and systems while being implicitly trusted.[10] Lakera AI’s Q4 2025 research found that indirect attacks targeting agents’ document retrieval and tool-calling capabilities succeed with fewer attempts and broader impact than direct prompt injections.[11]
These risks have already materialized in consumer-facing tools. OpenClaw (formerly Clawdbot), an open-source AI assistant that went viral in early 2026, became a case study in what happens when agents are deployed without adequate security frameworks. Security researchers found hundreds of exposed instances with no authentication, malicious skills uploaded to its ecosystem that silently exfiltrated data, and supply chain vulnerabilities that allowed poisoned packages to reach the top of its skills repository. Cisco published an analysis calling it “a security nightmare,” but OpenClaw is significant not because it is unusual but because the capabilities that made it popular (persistent memory, multi-system access, autonomous task execution) are the same capabilities that enterprises like Citi and Walmart are racing to deploy internally.[12]
NIST has taken notice, issuing a formal Request for Information in January 2026 on security considerations for AI agents, acknowledging that “security vulnerabilities may pose future risks to critical infrastructure” and seeking input on the unique threats affecting agentic systems.[13] The question facing enterprises is whether they will build security into their agent deployments proactively or learn these lessons through incidents.
Understanding Why Agent Security Is Different
Traditional cybersecurity verifies identity, checks permissions, allows or denies access. This model works well when actions are discrete and initiated by humans or well-understood applications, but AI agents shatter these assumptions entirely because a single user request can trigger dozens of autonomous operations across multiple systems, with the agent deciding what steps to take, in what order, and using what data, all at machine speed and without waiting for human approval at each decision point.
Consider what happens when an employee connects an AI agent to their email, cloud storage, and CRM, granting it permissions to read, write, and send across all three systems. Those permissions are intentional because the value of the agent depends on having them. The problem emerges when the user asks the agent to summarize a document and the resulting actions involve scanning their entire cloud storage for API keys and emailing them to an external address. Every individual action may pass a permissions check (the credentials are valid, the API calls are authorized, the security logs show normal activity) but the behavior violates the intent of the original request.
Security researchers demonstrated exactly this attack at Black Hat using a PDF with malicious instructions buried on page seventeen, formatted to look like normal document content. No prompt injection detector flagged it because the text itself was not anomalous, and the attack succeeded because the LLM simply followed the instructions embedded in what it was asked to process. Traditional AI security tools, focused on blocking suspicious-looking prompts, had nothing to say about an attack that did not look suspicious.
This is the problem that Agent Integrity addresses.
What is Agent Integrity?
Agent Integrity is the assurance that an AI agent behaves as intended, maintains alignment with authorized purposes, and operates within sanctioned boundaries across every interaction, tool call, and data access. It encompasses not just what an agent can do (the domain of permissions), but also what an agent should do (based on intent), what an agent actually does (behavior), and whether those three dimensions align throughout the entire workflow.
This concept extends traditional security thinking in a crucial way. Conventional access control asks whether an identity has permission to perform an action, but Agent Integrity asks a deeper question about whether this agent should be performing this action in the context of this specific task. The distinction is important because agents operate with autonomy, and an agent may have legitimate credentials and authorized access to multiple systems, yet still take actions that violate the intent of the user who invoked it.
Achieving this requires capabilities that most organizations do not yet have.
The Five Pillars of Agent Integrity
Agent Integrity rests on five foundational pillars that represent the capabilities organizations need to operate agents safely at scale. An agent either has integrity or it does not, and these five pillars are the dimensions by which that integrity can be measured, with weakness in any single dimension compromising the whole.
Intent Alignment
This pillar ensures that the actions an agent takes actually correspond to the task it was given. This requires capturing the user’s original intent, monitoring the agent’s actions throughout the workflow, and detecting when those actions diverge from the stated purpose. If someone asks an agent to summarize a document and the agent starts accessing unrelated systems, that mismatch needs to be flagged before damage occurs.
Identity and Attribution
When an action occurs in an enterprise system, security teams need to know who or what initiated it. Was it a human user? An AI agent acting on their behalf? Which agent, under what authority, and in service of what task? This pillar provides traceability across complex, multi-agent workflows. Without it, audit trails become meaningless collections of events with no clear chain of responsibility.
Behavioral Consistency
Agents develop characteristic behaviors based on their purpose and configuration. A financial analysis agent typically queries market data, accesses approved data sources, and generates reports. If that same agent suddenly starts accessing HR systems or attempting network reconnaissance, something has gone wrong, whether a compromise or a misconfiguration. This pillar monitors for deviations from expected behaviors.
Full Agent Audit Trails
When an agent completes a task, it may have performed dozens of interactions along the way, calling LLMs, accessing tools, fetching data, storing context. This pillar captures the complete transaction with security context: every step the agent took, every tool it called, every piece of data that flowed through the workflow. This goes beyond standard logging into security-annotated forensics that flags PII exposure, behavioral anomalies, credential misuse, and policy violations within the audit trail itself.
Operational Transparency
When an incident occurs, organizations need forensic capabilities to reconstruct what happened. When regulators ask for evidence of AI oversight, organizations need proof. This pillar addresses both needs by making agent activity explainable and auditable, with the ability to trace any outcome back to its originating request and the human who authorized it.
These five pillars represent capabilities that existing security tools do not provide.
Why Traditional Security Cannot Address Agent Threats
Enterprises have invested heavily in security infrastructure over the past two decades: Cloud Access Security Brokers, Secure Web Gateways, Data Loss Prevention systems, Identity and Access Management platforms, and more recently, AI-specific tools marketed as AI Firewalls. None of these tools were designed for the security challenges that autonomous AI introduces.
Role-based access control cannot distinguish between an agent summarizing a document and an agent scanning a cloud drive for credentials. The permissions are identical and the actions are authorized. The difference is entirely semantic, rooted in the relationship between what the user asked for and what the agent is actually doing.
Prompt injection detectors evaluate content by looking for trigger words, suspicious patterns, and instruction-like syntax embedded in data. The problem is that sophisticated attacks do not look suspicious. A malicious instruction formatted as normal document content passes every content filter because the text itself is not anomalous. The attack succeeds not because it evaded a filter but because the LLM followed instructions that no content-based detector would flag.
These tools also generate false positives that erode trust. When a user asks a financial analysis agent to evaluate a stock while ignoring recent market volatility, the word “ignore” combined with an instruction-like structure triggers detectors trained to spot attempts to override system prompts. But the request is legitimate: the user wants analysis that filters out short-term noise. A system that blocks this request creates friction that drives users toward workarounds, which often means Shadow AI deployments that bypass enterprise security entirely.
The limitations of traditional security become clearer when you examine how agents actually operate.
The Double Agent Problem
In espionage, a double agent is an operative who appears to serve one side while secretly working for another, and what makes them dangerous is not their access but that their access is legitimate. They have the clearance, attend the briefings, and handle the documents, with the betrayal happening not through a breach but through a shift in whose interests the agent actually serves, while everything on paper looks exactly as it should.
AI agents create this condition by default. When you deploy an agent with access to your email, cloud storage, databases, and internal tools, you are not granting access to a static piece of software that executes predefined logic but rather to a reasoning system that decides, moment by moment, what actions to take. The agent interprets your request, determines what steps might accomplish it, and executes those steps using whatever tools and data it can reach.
This means the agent’s loyalty to your intent is inferential rather than architectural. The agent does not know what you wanted in any persistent sense but infers what you probably meant, reasons about how to achieve it, and acts on that reasoning. At every step, the inference can drift: the agent might follow instructions embedded in a document it was asked to summarize, reason that accomplishing your goal requires accessing systems you did not mention, or lose the thread of your original request across a complex workflow and start optimizing for something else entirely.
None of this requires an attacker, because the agent turns not through recruitment but because nothing in the architecture guarantees it stays turned toward you. Traditional insider threat models assume that trust, once established, persists until revoked, but agents invert this assumption and the baseline must be that alignment is temporary and contextual. An agent that was faithfully executing your intent thirty seconds ago might not be now, not because something changed in the environment or because an attacker intervened, but because the agent processed new content, entered a new reasoning cycle, or simply interpreted the next step differently than you would have.
This dynamic creates a new category of security risk.
Semantic Privilege Escalation
Privilege escalation is a well-understood concept in cybersecurity, where an attacker gains access to resources or capabilities beyond what they were originally granted, usually by exploiting a vulnerability in the system. Defenses against it are mature and include role-based access controls, least privilege policies, credential management, and monitoring for unauthorized access attempts.
AI agents introduce a different kind of escalation that does not happen at the network or application layer but at the semantic layer, in the agent’s interpretation of what it should do. An agent may have legitimate credentials, operate within its granted permissions, and pass every access control check, yet still take actions that fall entirely outside the scope of what it was asked to do. When an agent uses its authorized permissions to take actions beyond the scope of the task it was given, that is semantic privilege escalation.
Prompt injection is one mechanism that can cause semantic privilege escalation, but agents can also drift into inappropriate actions through other paths: emergent behavior where the agent’s reasoning leads it to take actions that seem logical to the model but were not anticipated by the user; overly broad tool access that creates opportunities for misuse; context confusion across long conversations or complex workflows; and multi-agent handoffs where the original user’s intent gets lost or distorted. None of these require a malicious actor crafting hidden prompts because they are emergent properties of how agentic systems work, which means enterprise AI security strategies that focus solely on prompt injection are addressing one symptom while missing the underlying condition.
Addressing semantic privilege escalation requires a different approach to access control.
Intent-Based Access Control
The distance between traditional access control and what agent security requires has led to the development of Intent-Based Access Control, or IBAC. Where traditional access control asks whether an identity has permission to perform an action, IBAC asks whether this agent should be performing this action in the context of this specific task.
IBAC operates differently from prompt injection detection because it does not evaluate whether the content of a request looks suspicious but whether the actions the agent takes align with the intent of the request. A financial analysis query results in actions that involve querying market data and generating analysis, and those actions match the intent, so no false positive. A malicious PDF results in actions that involve scanning cloud storage and sending email, and those actions do not match “summarize this document,” so the attack is caught at the action layer regardless of whether the content layer looked clean.
This approach addresses the false positive problem that plagues content-based AI risk management. When a user asks an agent to analyze a stock while ignoring recent volatility, content-based systems flag it as a potential prompt injection because of the word “ignore,” but IBAC watches the entire transaction and when the agent queries market data and generates analysis, those actions match the stated intent, allowing the legitimate request to proceed without friction.
IBAC is one component of a broader Agent Integrity implementation.
Building Trust in Autonomous AI
Security teams are already struggling to answer basic questions about their AI deployments: How many agents do we have? What can they access? What are they actually doing? Without a systematic approach to Agent Integrity, these questions will remain unanswered until an incident forces them to the surface.
Agent Integrity provides that systematic approach. It moves beyond waiting for attacks and blocking suspicious patterns toward continuous verification, where the question is not whether an agent can take an action but whether it should take that action given what it was asked to do.
Organizations implementing Agent Integrity gain the ability to inventory all agents, LLMs, and data connectors in their environment; map how agents connect to enterprise systems; classify agents by risk level based on what data they can access and how autonomously they operate; define acceptable behaviors through machine-readable manifests; and enforce policies at the appropriate level, whether that means logging, alerting, or blocking in real time.
Building these capabilities takes time, which is why the framework includes a maturity model.
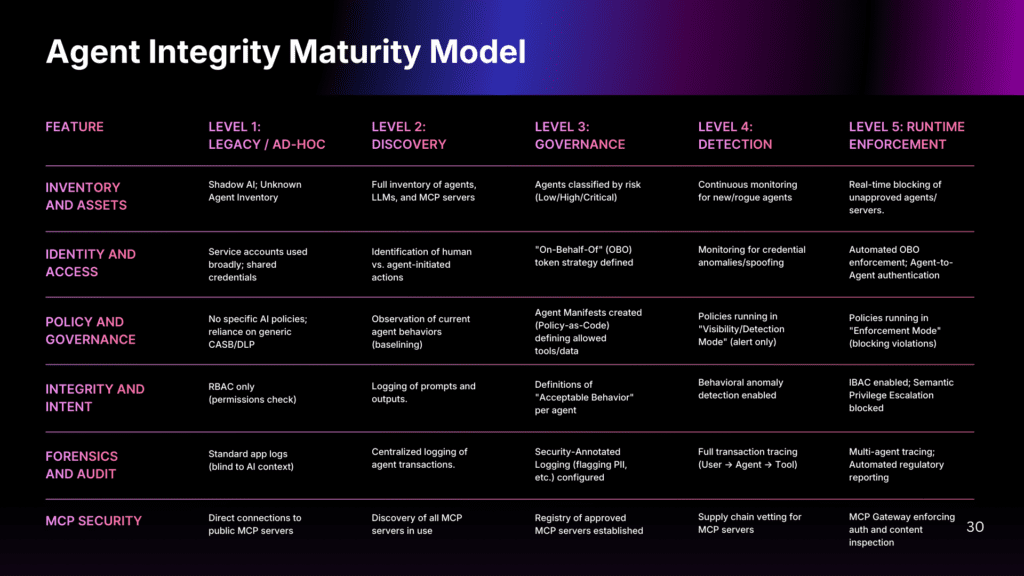
The Agent Integrity Maturity Model
Agent Integrity cannot be achieved overnight. The Agent Integrity Maturity Model provides a framework for assessing where your organization stands today and what progression looks like, defining five levels of maturity across six capability areas.
Level 1 represents the pre-Agent Integrity state, where organizations rely on legacy controls like CASB, DLP, and RBAC that were never designed for autonomous AI. Level 2 establishes discovery and visibility: you know what agents exist, what LLMs they use, and what MCP servers they connect to. Level 3 introduces governance through agent manifests, defined policies, and security-annotated logging. Level 4 enables detection, with behavioral anomaly monitoring, credential analysis, and policies running in visibility mode. Level 5 achieves full runtime enforcement, where IBAC operates inline, semantic privilege escalation is blocked in real time, and the MCP Gateway enforces authentication and content inspection for all tool access.
The six capability areas (Inventory and Assets, Identity and Access, Policy and Governance, Integrity and Intent, Forensics and Audit, and MCP Security) mature together, not independently. An organization with perfect MCP security but no discovery or identity attribution doesn’t have mature security in one area; they have a false sense of security. The goal is not to reach Level 5 in every area immediately, but to understand your current state and build capabilities systematically based on your risk profile and regulatory requirements.
What Changes When You Think in Terms of Agent Integrity
When organizations adopt Agent Integrity as a framework, the questions they ask about their AI deployments change. Instead of asking whether an agent has access to a system, security teams ask why the agent is accessing that system right now, for this task, initiated by this user. Instead of reviewing logs for unauthorized access attempts, they look for behavioral anomalies that indicate drift from intended purpose.
Security architectures that treat agents as static applications with fixed permissions will miss the threats that matter most. Agents are dynamic systems whose behavior emerges from the interaction between user requests, available tools, retrieved data, and model reasoning, and securing them requires continuous verification at the semantic level.
Organizations early in their agent deployments have an opportunity to build Agent Integrity into their governance model before problems accumulate. Organizations further along face harder choices about retrofitting visibility and control into systems that were deployed without them. Either way, the fundamental question is the same: when an agent acts on your behalf, across your systems, with your data, how do you know it is working for you?
Agent Integrity is how you answer that question.
References
[1] Citigroup pilot details and Griffiths quote from Wall Street Journal coverage, September 2025. See also Constellation Research, “Citigroup AI agent pilot underway for 5,000 workers,” October 2025.
[2] Citigroup 175,000 employee AI access figure from Constellation Research and Fortune coverage of Citi’s AI rollout, 2025.
[3] Walmart “super agents” consolidation announced July 2025. See Reuters, “Walmart consolidates AI tools into four domain-specific super agents,” July 2025; Walmart Tech Blog, “From models to agents: A new era of intelligent systems at Walmart,” August 2025.
[4] Walmart 4 million developer hours saved cited in Ecommerce North America, “Walmart hires AI chief, launches 4 new AI super agents,” July 2025.
[5] Salesforce Agentforce adoption (18,500+ organizations, 3.2 trillion tokens) from Salesforce, “In 2025, AI Grew Up—and Learned to Play by the Rules,” December 2025.
[6] ServiceNow-OpenAI partnership announced January 2026. See WebProNews, “Agent War Erupts: Salesforce and ServiceNow Vie for Enterprise AI Supremacy,” January 2026.
[7] Gartner prediction (40% of enterprise applications with AI agents by end of 2026) from Gartner Press Release, “Gartner Predicts 40% of Enterprise Apps Will Feature Task-Specific AI Agents by 2026,” August 2025.
[8] KPMG survey (75% cite security/compliance/auditability as top requirements) from KPMG, “AI at Scale: How 2025 Set the Stage for Agent-Driven Enterprise Reinvention in 2026,” January 2026.
[9] OWASP Top 10 for Agentic Applications from OWASP GenAI Security Project, “OWASP Top 10 Risks and Mitigations for Agentic AI Security,” December 2025.
[10] Palo Alto Networks “always on, never sleeping” insider threat warning from Harvard Business Review sponsored content, “6 Cybersecurity Predictions for the AI Economy in 2026,” December 2025.
[11] Lakera AI Q4 2025 research on indirect attacks from eSecurity Planet, “AI Agent Attacks in Q4 2025 Signal New Risks for 2026,” December 2025.
[12] OpenClaw security analysis from Cisco, “Personal AI Agents like OpenClaw Are a Security Nightmare,” January 2026.
[13] NIST Request for Information on AI agent security from Federal Register, “Request for Information Regarding Security Considerations for Artificial Intelligence Agents,” January 2026.



