Acuvity Joins Proofpoint — Powering the Future of AI Security at Enterprise Scale
We’re now part of Proofpoint’s unified cybersecurity platform, combining Acuvity’s AI-native security and governance with world-class protection for people, data, and agents — securing AI everywhere it works.
2025 State of
AI Security Report
What the latest data reveals about AI risk, budgets and biggest threats ahead.
2026 Cybersecurity Predictions
Discover Acuvity's AI Security Platform
AI Runtime Security to protect your users, AI applications and agents.

Gen AI threats are adapting faster than legacy security can keep up – Acuvity's RYNO brings clarity and control to the chaos.
possibilitiesMeet the Industry's Only Complete
AI Security Platform.
The platform built to secure your AI ecosystem.
Acuvity unifies discovery, governance, data protection, and runtime defense into one platform. It is easy to get started with a simple AI risk audit that shows where Shadow AI is in use, what data is at risk, and how policies can be applied.
From there, enterprises gain continuous visibility, enforcement aligned to regulations such as GDPR, HIPAA, and PCI, and protection against threats including data leakage, IP loss, and model manipulation.
Whether securing copilots, agents, embedded AI in SaaS, or emerging protocols like MCP, Acuvity gives security teams a complete and practical way to bring AI under control.
Instant Time to Value
Get Protected in Minutes, Not Months.
Acuvity's RYNO platform delivers immediate AI security without lengthy deployments or complex configurations. Start seeing your complete AI footprint, detect shadow AI, and enforce policies from day one. No waiting for integrations, no extended rollouts. Get instant visibility and control across your entire AI ecosystem.
Comprehensive Risk Reduction
Turn AI Blind Spots Into Total Visibility.
Reduce AI security risks with comprehensive coverage across every user, application, and AI interaction. Acuvity RYNO provides comprehensive risk reduction by uncovering hidden threats, unauthorized tools, and compliance gaps before they become costly incidents.
Continuous Runtime Inspection and Enforcement
Real-Time Protection During Every AI Interaction.
Protect your organization during AI usage with continuous security and real-time threat detection. Acuvity RYNO monitors every prompt, response, and interaction to detect and block threats as they happen.
Effortless AI Compliance
Stay Compliant Without the Complexity.
Meet your regulatory compliance and AI governance requirements without the manual overhead. Acuvity RYNO ensures your AI usage meets GDPR, HIPAA, SOC 2, and other regulatory requirements with built in audit trails, streamlined reporting, and policy enforcement that adapts to changing regulations.
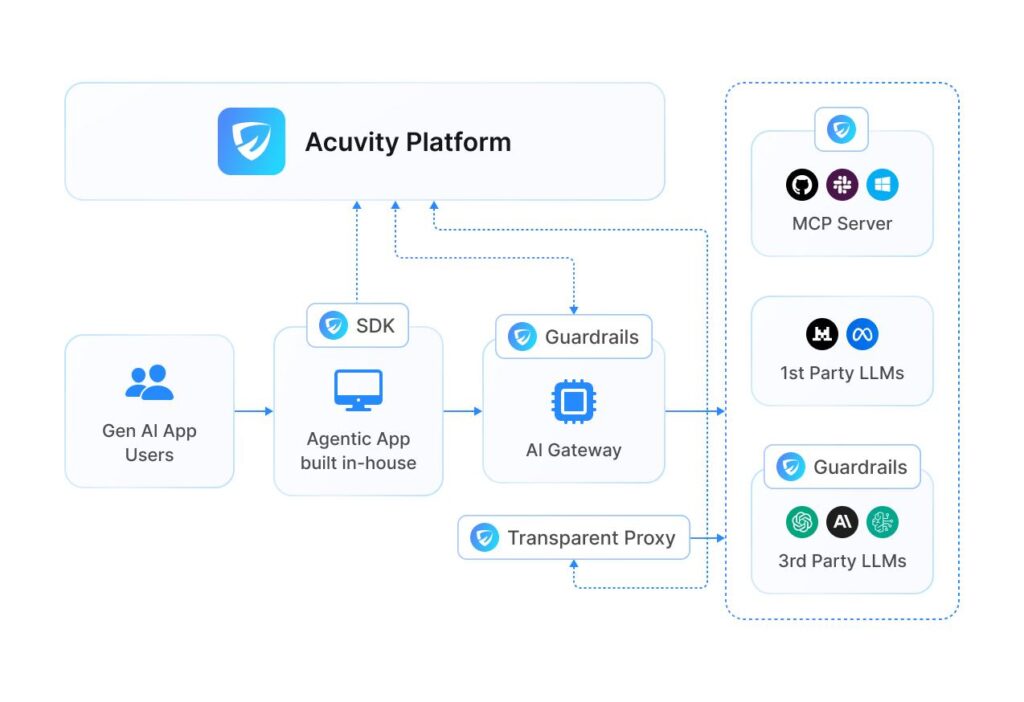
ACUVITY RYNO - AI SECURITY PLATFORMThe Future-Proof AI Security Platform Architecture
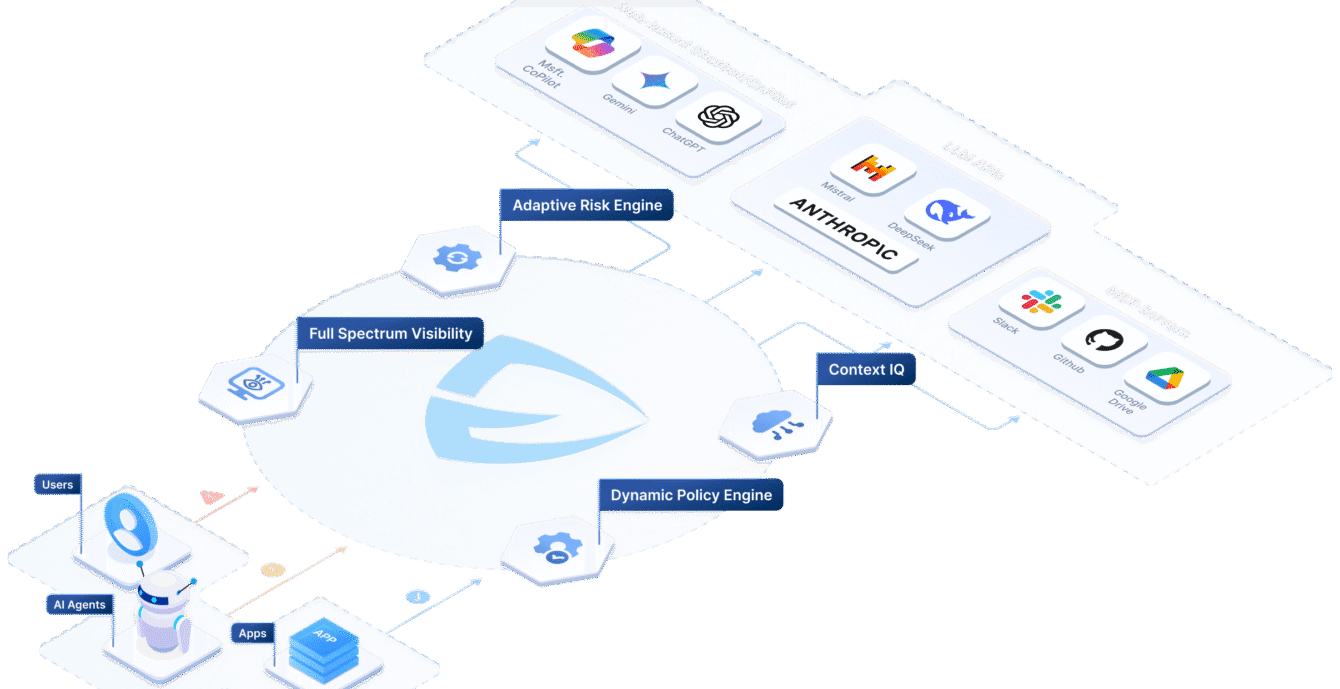
Acuvity's RYNOCore Capabilities
RYNO Offers Broad Core Capability Coverage for AI Operational Governance and Runtime Security in a Single Platform
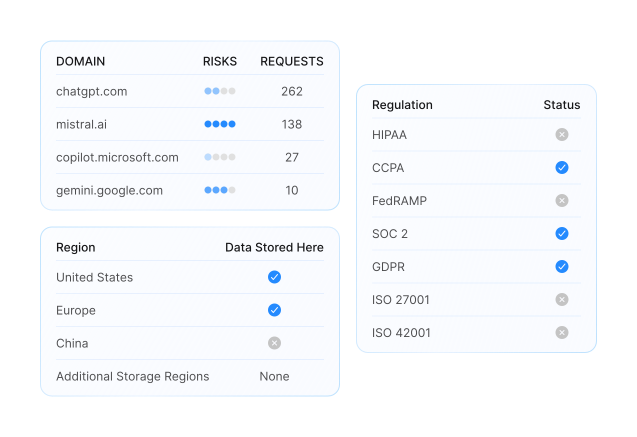
Shadow AI Discovery
Unapproved AI use exposes sensitive data and creates compliance risk. From copilots and chatbots to embedded AI in SaaS and developer tools, this usage happens outside security oversight. Acuvity finds unapproved and unknown tools, shows who is using them and how, and applies enterprise policies so Shadow AI is governed instead of ignored.
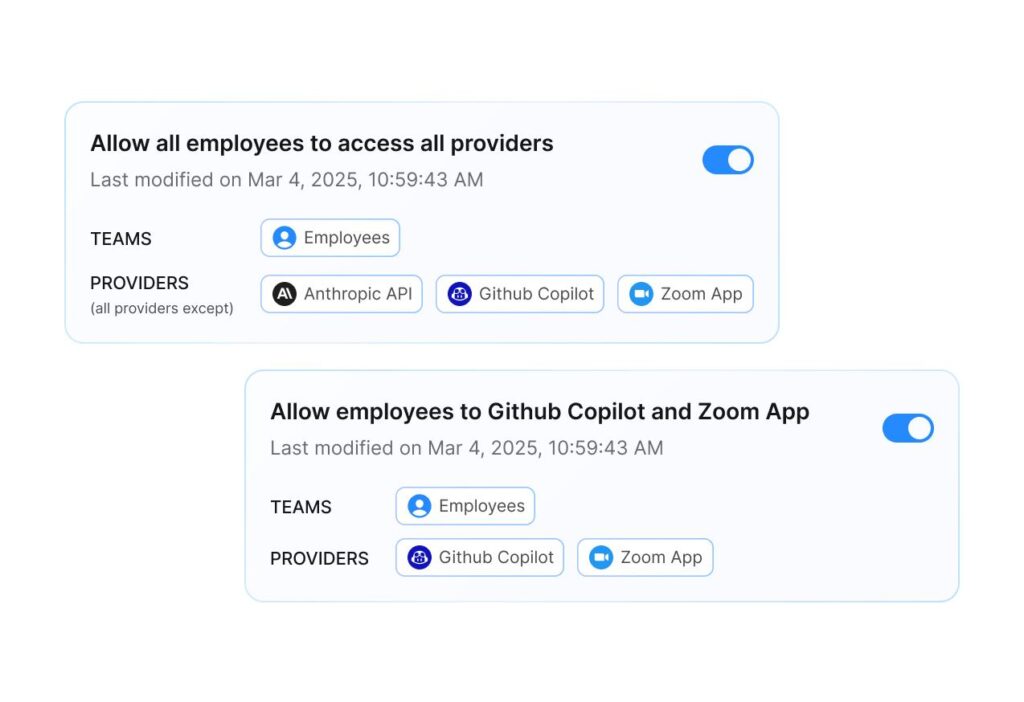
Threat Protection
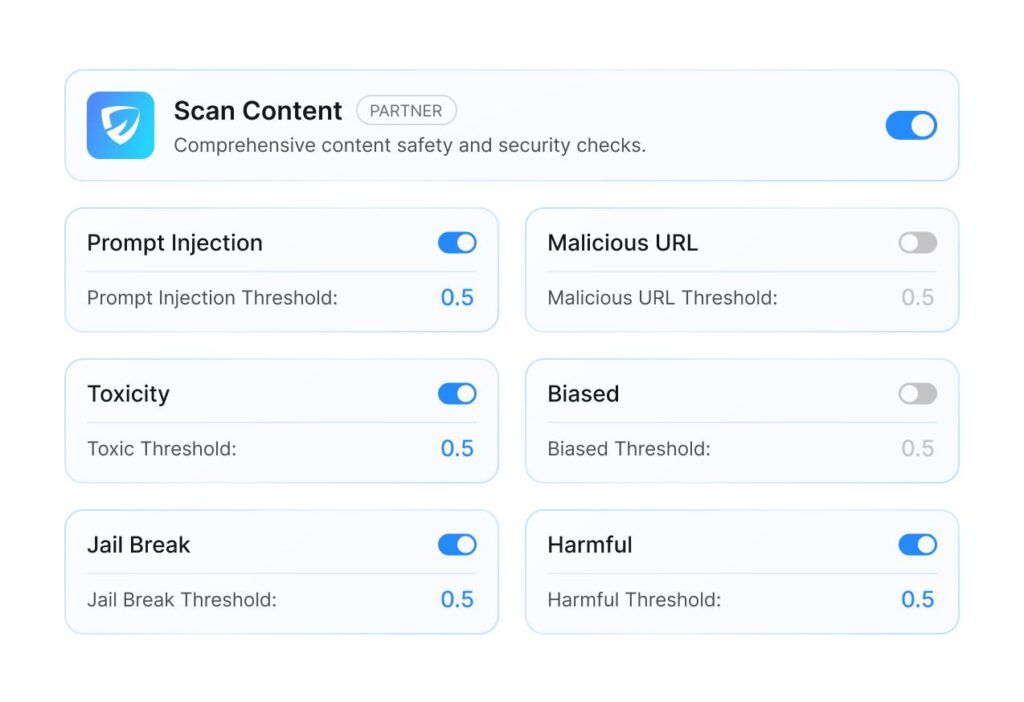
Prompt injection, jailbreaks, and malicious instructions can manipulate models and expose sensitive data. Acuvity inspects AI activity in real time, applies enterprise policies to every interaction, and contains malicious behavior before it impacts the business.
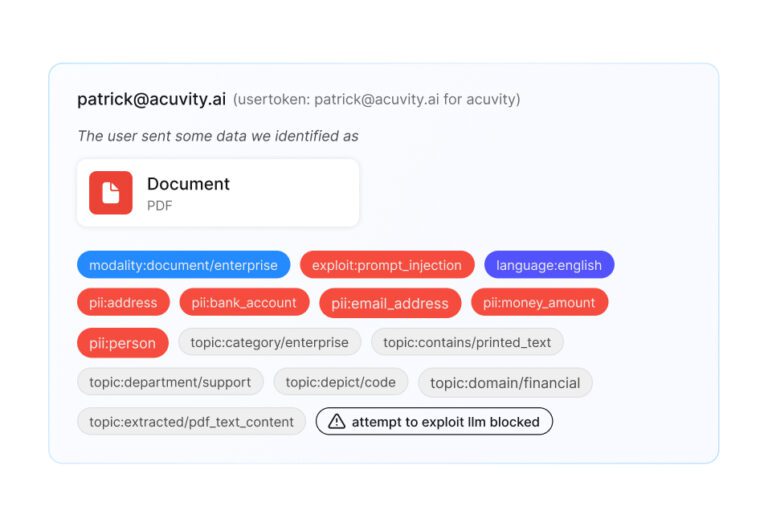
Advanced Data Protection
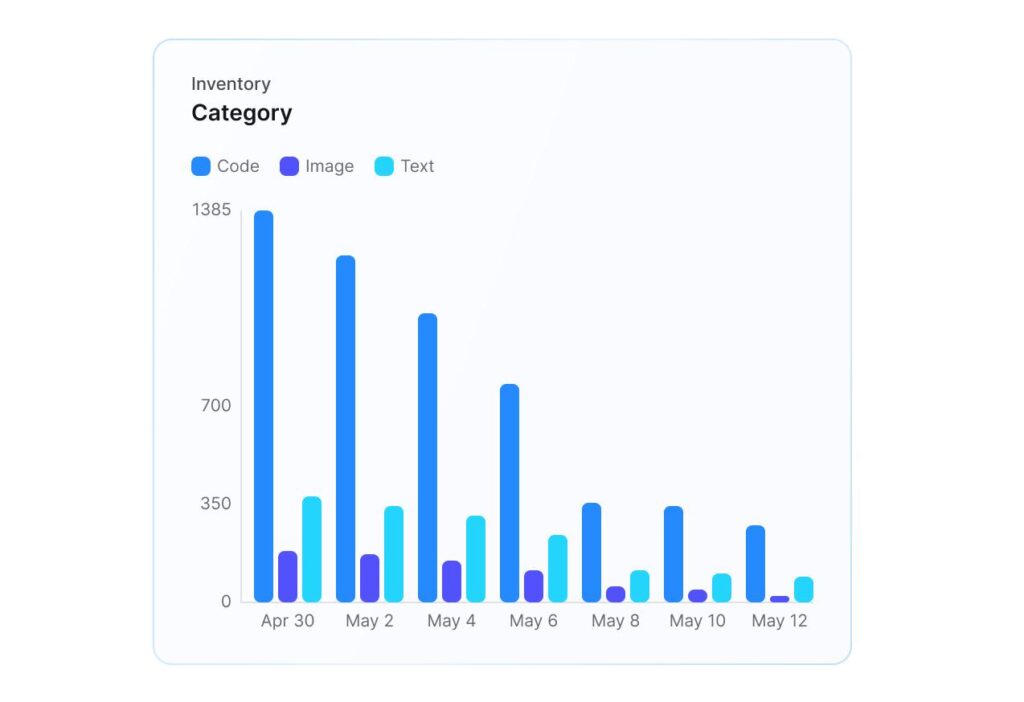
Acuvity inspects and controls data flowing into and out of AI tools across text, code, images, and other data types. Enterprise policies are enforced in real time to protect sensitive information, prevent exposure to untrusted services, and maintain compliance with GDPR, HIPAA, PCI, and other standards.
AI Firewall
Attacks against AI take forms such as prompt injection, model manipulation, and malicious inputs designed to extract or corrupt data. These techniques can alter outputs, expose confidential information, and gain unauthorized access through integrations and APIs. Acuvity inspects requests in real time, evaluates behavior for signs of manipulation, and enforces enterprise policies to contain threats before they impact the business.
AI Runtime Security
AI activity cannot be fully evaluated until it's in production. At runtime, agents execute tasks, models process sensitive data, and integrations connect directly into business workflows. Acuvity monitors these interactions in real time, applies enterprise policies as actions occur, and prevents misuse or data exposure without interrupting legitimate use.
MCP Server Security
The Model Context Protocol opens powerful new connections between AI assistants, enterprise tools, and data, but it also introduces risk when servers are misconfigured or unprotected. Acuvity secures MCP by hardening servers with least-privilege execution, immutable runtimes, and continuous vulnerability scanning, while Minibridge adds TLS, authentication, and threat detection to close protocol gaps.
With automated deployment across Kubernetes, Docker, and leading IDEs, organizations can adopt MCP with the assurance of enterprise-grade security and compliance.
blogStay Informed
About AI Security

")

Want to learn how Acuvity can help your organization Govern and Secure AI at scale? Let’s talk.

Location
111 W Evelyn Ave, Suite 119
Sunnyvale, CA 94086